
Bài viết dựa trên Chương 2 cuốn sách: Grrokking Deep learning
“Đừng lo lắng về việc khó khăn của bạn trong học toán học. Tôi có thể đảm bảo bạn vẫn tốt hơn tôi – Albert Einstein”
Nội dung chính
1. Học sâu, học máy và trí tuệ nhân tạo là gì
Học sâu là gì?
Học sâu là một tập con của học máy, là một lĩnh vực dành riêng cho việc nghiên cứu và phát triển các máy móc có thể học hỏi (đôi khi với mục tiêu cuối cùng đạt được trí tuệ nhân tạo nói chung). Trong công nghiệp, học sâu được sử dụng để giải quyết các nhiệm vụ thực tế trong nhiều lĩnh vực khác nhau như thị giác máy tính (hình ảnh), xử lý ngôn ngữ tự nhiên (văn bản) và nhận dạng giọng nói tự động (âm thanh). Tóm lại, học sâu là một tập hợp con của các phương pháp trong hộp công cụ học máy, chủ yếu sử dụng mạng thần kinh nhân tạo, là một lớp thuật toán lấy cảm hứng từ bộ não người.Học máy là gì
Thông thường khi bạn lập trình bạn sẽ tạo ra những quy tắc nhưng với học máy bạn sẽ học được từ các dự liệu, nghĩa là từ dữ liệu tạo ra các quy luật và như vậy máy có thể học được. Theo Arthur Samuel thì học một lĩnh vực nghiên cứu cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình rõ ràng. Cho rằng học sâu là một tập con của học máy, học máy là gì? Nói chung, nó là những gì tên của nó ngụ ý. Học máy là một lĩnh vực con của khoa học máy tính, trong đó máy học cách thực hiện các tác vụ mà chúng không được lập trình rõ ràng. Nói tóm lại, máy móc quan sát một mẫu và cố gắng bắt chước theo một cách nào đó có thể là trực tiếp hoặc gián tiếp. Trong bài viết này đề cập học mấy gồm 2 dạng: học máy trực tiếp và gián tiếp như một sự song song của hai loại học máy chính: có giám sát và không giám sát. Học máy có giám sát là sự bắt chước trực tiếp một mẫu giữa hai tập dữ liệu. Nó luôn luôn Cố gắng lấy một tập dữ liệu đầu vào và chuyển nó thành tập dữ liệu đầu ra. Đây có thể là một khả năng vô cùng mạnh mẽ và hữu ích. Hãy xem xét các ví dụ sau (tập dữ liệu đầu vào in đậm và tập dữ liệu đầu ra in nghiêng): – Sử dụng các pixel của hình ảnh để phát hiện sự hiện diện hoặc vắng mặt của một con mèo – Sử dụng những bộ phim bạn thích để dự đoán những bộ phim khác mà bạn có thể thích – Sử dụng lời nói của ai đó để dự đoán xem họ đang vui hay buồn – Sử dụng dữ liệu cảm biến thời tiết để dự đoán xác suất mưa – Sử dụng cảm biến động cơ ô tô để dự đoán các cài đặt điều chỉnh tối ưu – Sử dụng dữ liệu tin tức để dự đoán giá cổ phiếu ngày mai – Sử dụng một số đầu vào để dự đoán một số nhân đôi kích thước của nó – Sử dụng tệp âm thanh thô để dự đoán bản ghi âm thanh Đây là một số bài toán mà học máy giám sát giải quyết. Trong mọi trường hợp, thuật toán học máy đang cố gắng bắt chước mẫu giữa hai tập dữ liệu theo cách mà nó có thể sử dụng một tập dữ liệu này để dự đoán tập dữ liệu kia. Đối với bất kỳ ví dụ, hãy tưởng tượng nếu bạn có khả năng dự đoán tập dữ liệu đầu ra chỉ đưa ra tập dữ liệu đầu vào. Một khả năng như vậy sẽ rất sâu sắc đúng không?3. Học giám sát và học không giám sát là gì?
Học máy giám sát
Học tập có giám sát là một phương pháp để chuyển đổi một tập dữ liệu này thành một tập dữ liệu khác. Ví dụ: nếu bạn có tập dữ liệu được gọi là Giá cổ phiếu thứ Hai ghi lại giá của mọi cổ phiếu vào thứ Hai hàng tuần trong 10 năm qua và tập dữ liệu thứ hai được gọi là Giá cổ phiếu thứ Ba được ghi lại trong cùng một khoảng thời gian, thì một thuật toán học có giám sát có thể cố gắng sử dụng cái này để dự đoán cái kia. Nếu bạn đã đào tạo thành công thuật toán học máy có giám sát vào các ngày thứ Hai và thứ Ba trong 10 năm, thì bạn có thể dự đoán giá cổ phiếu vào bất kỳ ngày thứ Ba nào trong tương lai dựa trên giá cổ phiếu vào ngày thứ Hai ngay trước đó. Tôi khuyến khích bạn dừng lại và xem xét điều này trong giây lát. Máy học có giám sát là bánh mì và bơ của trí tuệ nhân tạo ứng dụng (còn được gọi là AI hẹp). Nó hữu ích khi lấy những gì bạn biết làm đầu vào và nhanh chóng chuyển đổi nó thành những gì bạn muốn biết. Điều này cho phép các thuật toán học máy được giám sát để mở rộng trí thông minh và khả năng của con người theo nhiều cách dường như vô tận. Phần lớn công việc sử dụng máy học dẫn đến việc đào tạo một bộ phân loại có giám sát nào đó.Học máy không giám sát
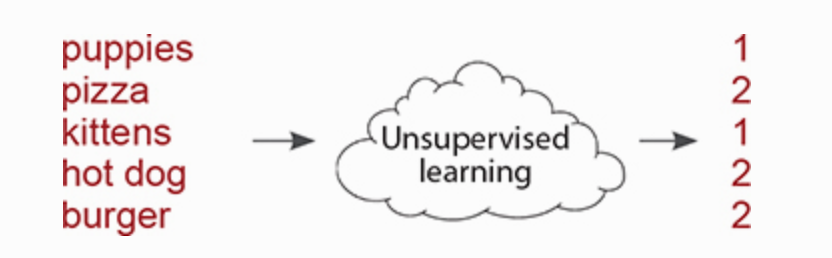
Học không giám sát chia sẻ một đặc tính chung với học có giám sát: nó biến đổi một tập dữ liệu này thành một tập dữ liệu khác. Nhưng tập dữ liệu mà nó biến đổi thành chưa được biết đến hoặc hiểu trước đây. Không giống như học tập có giám sát, không có “câu trả lời đúng” mà bạn đang cố gắng làm cho mô hình trùng lặp. Bạn chỉ cần ra lệnh cho một thuật toán không được giám sát “tìm các mẫu trong dữ liệu này và cho tôi biết về chúng”. Ví dụ, nhóm một tập dữ liệu thành các nhóm là một kiểu học tập không có giám sát. Phân cụm biến đổi một chuỗi các điểm dữ liệu thành một chuỗi các nhãn cụm. Nếu nó học được 10 cụm, thông thường các nhãn này sẽ là các số từ 1–10. Mỗi điểm dữ liệu sẽ được gán cho một số dựa trên cụm dữ liệu đó nằm trong nhóm nào. Do đó, tập dữ liệu biến từ một nhóm điểm dữ liệu thành một nhóm nhãn. Tại sao các nhãn là số? Thuật toán không cho bạn biết các cụm là gì. Làm sao nó có thể biết được? Nó chỉ nói, “Này nhà khoa học! Tôi đã tìm thấy một số cấu trúc. Có vẻ như có các nhóm trong dữ liệu của bạn. Họ đây rồi! (Ơn giời cậu đây rồi =))






{kind=link}