
Nội dung chính
Lọc cộng tác là gì
Lọc cộng tác là một kỹ thuật có thể lọc ra các mục mà người dùng có thể thích trên cơ sở phản ứng của những người dùng tương tự. Nó hoạt động bằng cách tìm kiếm một nhóm lớn người và tìm một nhóm người dùng nhỏ hơn có thị hiếu tương tự như một người dùng cụ thể. Nó xem xét các mục họ thích và kết hợp chúng để tạo ra một danh sách đề xuất được xếp hạng. Có nhiều cách để quyết định người dùng nào giống nhau và kết hợp các lựa chọn của họ để tạo danh sách đề xuất. Bài viết này sẽ hướng dẫn bạn cách thực hiện điều đó với Python. Hầu hết các trang web như Amazon, YouTube và Netflix sử dụng tính năng lọc cộng tác như một phần của hệ thống recommender của họ. Bạn có thể sử dụng kỹ thuật này để xây dựng ứng dụng đưa ra đề xuất cho người dùng trên cơ sở lượt thích và không thích của những người dùng tương tự.Dữ liệu
Với bất kì bài toán học máy nào thì việc đầu tiên chúng ta cần chuẩn bị đó là data. Để thử nghiệm với các thuật toán đề xuất, bạn sẽ cần dữ liệu chứa một tập hợp các mục và một tập hợp người dùng đã phản ứng với một số mục. Phản ứng có thể rõ ràng (đánh giá trên thang điểm từ 1 đến 5, thích hoặc không thích) hoặc ngầm (xem một mục, thêm nó vào danh sách mong muốn, thời gian dành cho một bài báo). Trong khi làm việc với những dữ liệu như vậy, hầu như bạn sẽ thấy nó ở dạng ma trận bao gồm các phản ứng do một nhóm người dùng đưa ra đối với một số mục từ một nhóm các mục. Mỗi hàng sẽ chứa các xếp hạng do người dùng đưa ra và mỗi cột sẽ chứa các xếp hạng mà một mục nhận được. Một ma trận với năm người dùng và năm mục có thể trông như thế này: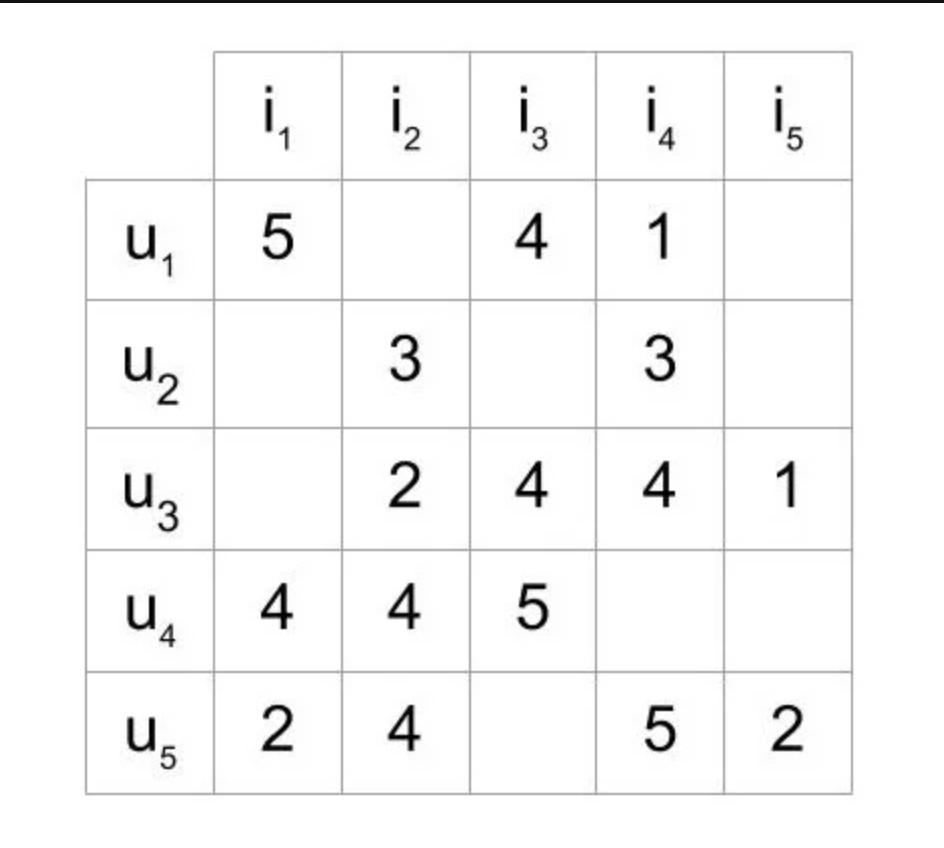
Ma trận hiển thị năm người dùng đã xếp hạng một số mặt hàng trên thang điểm từ 1 đến 5. Ví dụ: người dùng đầu tiên đã xếp hạng 4 cho mặt hàng thứ ba.
Trong hầu hết các trường hợp, các ô trong ma trận trống vì người dùng chỉ xếp hạng một vài mục. Rất khó có khả năng mọi người dùng đánh giá hoặc phản ứng với mọi mặt hàng có sẵn. Một ma trận với hầu hết các ô trống được gọi là thưa và ngược lại với ma trận đó (ma trận chủ yếu được lấp đầy) được gọi là dày đặc.
Có rất nhiều bộ dữ liệu đã được thu thập và cung cấp cho công chúng để nghiên cứu và đánh giá tiêu chuẩn. Dưới đây là danh sách các nguồn dữ liệu chất lượng cao mà bạn có thể chọn.
Tốt nhất để bắt đầu sẽ là tập dữ liệu MovieLens do GroupLens Research thu thập. Đặc biệt, tập dữ liệu MovieLens 100k là tập dữ liệu chuẩn ổn định với 100.000 xếp hạng do 943 người dùng đưa ra cho 1682 phim, với mỗi người dùng đã xếp hạng ít nhất 20 phim.
Tập dữ liệu này bao gồm nhiều tệp chứa thông tin về phim, người dùng và xếp hạng do người dùng đưa ra cho phim họ đã xem. Những thứ được quan tâm là:
u.item: danh sách phim
u.data: danh sách xếp hạng do người dùng đưa ra
Tệp u.data chứa xếp hạng là danh sách được phân tách bằng tab gồm ID người dùng, ID mục, xếp hạng và dấu thời gian. Vài dòng đầu tiên của tệp trông như thế này:
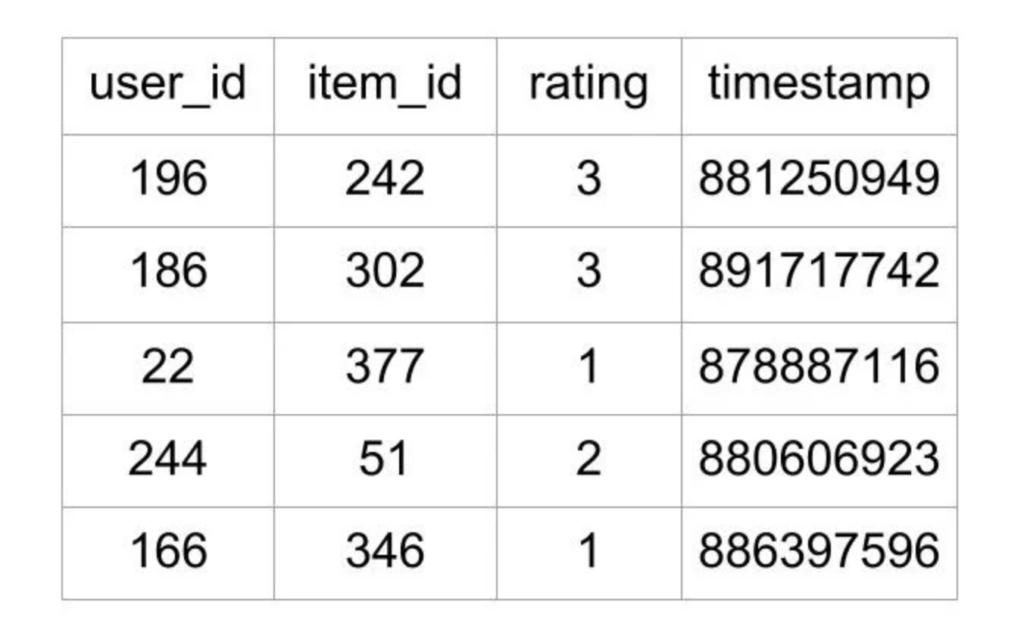
Như đã nói ở trên, tệp chỉ ra cái nào là đánh giá của người dùng đưa ra cho mỗi video. Tệp bao gồm 100000 ratings, cái mà sẽ giúp dự đoán những ratings của movié không nhìn thấy bởi người dùng.
Các bước liên Quan
Để xây dựng một hệ thống có thể tự động giới thiệu mặt hàng cho người dùng dựa trên sở thích của người dùng khác, bước đầu tiên là tìm người dùng hoặc mặt hàng tương tự. Bước thứ hai là dự đoán xếp hạng của các mục chưa được người dùng xếp hạng. Vì vậy, bạn sẽ cần câu trả lời cho những câu hỏi này:
- Làm cách nào để bạn xác định người dùng hoặc mặt hàng nào tương tự với nhau?
- Cho rằng bạn biết những người dùng nào tương tự nhau, làm cách nào để xác định xếp hạng mà người dùng sẽ cung cấp cho một mặt hàng dựa trên xếp hạng của những người dùng tương tự?
- Làm thế nào để bạn đo lường độ chính xác của xếp hạng bạn tính toán?
Hai câu hỏi đầu tiên không có câu trả lời duy nhất. Lọc cộng tác là một nhóm thuật toán trong đó có nhiều cách để tìm người dùng hoặc mục tương tự và nhiều cách để tính toán xếp hạng dựa trên xếp hạng của những người dùng tương tự. Tùy thuộc vào lựa chọn bạn thực hiện, bạn sẽ có một loại phương pháp lọc cộng tác.
Một điều quan trọng cần lưu ý là trong cách tiếp cận hoàn toàn dựa trên lọc cộng tác, sự tương đồng không được tính toán bằng cách sử dụng các yếu tố như độ tuổi của người dùng, thể loại phim hoặc bất kỳ dữ liệu nào khác về người dùng hoặc mục. Nó chỉ được tính toán dựa trên xếp hạng (rõ ràng hoặc ẩn ý) mà người dùng cung cấp cho một mặt hàng.
Ví dụ: hai người dùng có thể được coi là tương tự nhau nếu họ đưa ra cùng xếp hạng cho mười phim mặc dù có sự khác biệt lớn về tuổi tác của họ.
Câu hỏi thứ ba về cách đo lường độ chính xác của các dự đoán của bạn cũng có nhiều câu trả lời, bao gồm các kỹ thuật tính toán sai số có thể được sử dụng ở nhiều nơi và không chỉ những người đề xuất dựa trên lọc cộng tác.
Một trong những cách tiếp cận để đo độ chính xác của kết quả của bạn là Lỗi bình phương trung bình gốc (RMSE), trong đó bạn dự đoán xếp hạng cho tập dữ liệu thử nghiệm của các cặp mục người dùng có giá trị xếp hạng đã được biết trước. Sự khác biệt giữa giá trị đã biết và giá trị dự đoán sẽ là sai số. Bình phương tất cả các giá trị lỗi cho tập kiểm tra, tìm giá trị trung bình (hoặc giá trị trung bình), sau đó lấy căn bậc hai của giá trị trung bình đó để lấy RMSE.
Một số liệu khác để đo độ chính xác là Sai số tuyệt đối trung bình (MAE), trong đó bạn tìm độ lớn của lỗi bằng cách tìm giá trị tuyệt đối của nó và sau đó lấy giá trị trung bình của tất cả các giá trị lỗi.
Bạn không cần phải lo lắng về các chi tiết của RMSE hoặc MAE tại thời điểm này vì chúng có sẵn như một phần của các gói khác nhau trong Python.
Bây giờ, hãy xem xét các loại thuật toán khác nhau trong nhóm lọc cộng tác.
Dữa trên bộ nhớ
Loại đầu tiên bao gồm các thuật toán dựa trên bộ nhớ, trong đó các kỹ thuật thống kê được áp dụng cho toàn bộ tập dữ liệu để tính toán các dự đoán.
Để tìm xếp hạng R mà người dùng U sẽ cho một mục I, cách tiếp cận bao gồm:
- Tìm những người dùng tương tự như U đã xếp hạng mục I
- Tính xếp hạng R dựa trên xếp hạng của người dùng được tìm thấy ở bước trước
Cách tìm người dùng tương tự trên cơ sở xếp hạng
Để hiểu khái niệm về sự giống nhau, trước tiên chúng ta hãy tạo một tập dữ liệu đơn giản.
Dữ liệu bao gồm bốn người dùng A, B, C và D, những người đã xếp hạng hai bộ phim. Xếp hạng được lưu trữ trong danh sách và mỗi danh sách có hai số cho biết xếp hạng của từng phim:
- Xếp hạng của A là [1,0, 2,0].
- Xếp hạng của B là [2.0, 4.0].
- Xếp hạng của C là [2,5, 4,0].
- Xếp hạng của D là [4,5, 5,0].
Để bắt đầu với manh mối trực quan, hãy vẽ biểu đồ xếp hạng của hai bộ phim do người dùng đưa ra trên biểu đồ và tìm kiếm một mẫu. Biểu đồ trông như sau:

dựa trên biểu đồ trên, mỗi điểm tượng trung cho người dùng và nó được vẽ dựa trên 2 video. Nhìn vào khoảng cách giữa các điểm dường như là một cách tốt để đánh giá độ tương tương tự? Bạn có thể tìm khoảng cách bằng cách sử dụng công thức đo khoảng cách giữa 2 điểm bằng python như sau:
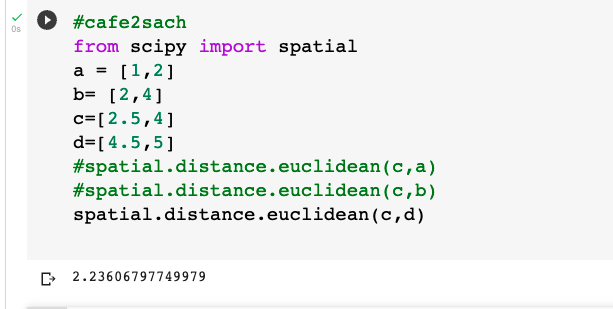
Như hình trên, bạn có thể sử dụng scipy.spatial.distance.euclidean để tính khoảng cách giữa hai điểm. Sử dụng nó để tính toán khoảng cách giữa xếp hạng của A, B và D so với xếp hạng của C cho chúng ta thấy rằng về khoảng cách, xếp hạng của C gần nhất với xếp hạng của B.
Bạn có thể thấy rằng người dùng C gần nhất với B ngay cả khi nhìn vào biểu đồ. Nhưng ngoài A và D, C tương tự với ai hơn?
Bạn có thể nói C gần D hơn về khoảng cách. Nhưng nhìn vào bảng xếp hạng, có vẻ như lựa chọn của C sẽ phù hợp với A hơn là D vì cả A và C đều thích bộ phim thứ hai gần gấp đôi so với bộ phim đầu tiên, nhưng D thích cả hai bộ phim đó. bằng nhau.
Vì vậy, bạn có thể sử dụng gì để xác định các mẫu mà khoảng cách Euclide không thể? Có thể sử dụng góc giữa các đường nối các điểm với điểm gốc để đưa ra quyết định không? Bạn có thể xem góc giữa các đường nối điểm gốc của biểu đồ với các điểm tương ứng như hình minh họa:

Biểu đồ cho thấy bốn đường nối mỗi điểm đến điểm gốc. Các đường thẳng của A và B trùng nhau, làm cho góc giữa chúng bằng không.
Bạn có thể xem xét rằng, nếu góc giữa các đường được tăng lên, thì độ tương đồng giảm xuống, và nếu góc bằng 0, thì người dùng rất giống nhau.
Để tính độ tương tự bằng cách sử dụng góc, bạn cần một hàm trả về độ tương tự cao hơn hoặc khoảng cách nhỏ hơn cho góc thấp hơn và độ tương tự thấp hơn hoặc khoảng cách lớn hơn cho góc cao hơn. Côsin của một góc là một hàm giảm từ 1 đến -1 khi góc tăng từ 0 đến 180.
Bạn có thể sử dụng cosin của góc để tìm sự giống nhau giữa hai người dùng. Góc càng cao, cosine sẽ càng thấp và do đó, mức độ tương đồng của người dùng càng thấp. Bạn cũng có thể nghịch đảo giá trị của cosin của góc để có được khoảng cách cosin giữa những người dùng bằng cách trừ nó cho 1. scipy có một chức năng tính khoảng cách cosin của các vectơ. Nó trả về giá trị cao hơn cho góc cao hơn:

Còn tiếp các phần sau mình sẽ đăng ở phần thứ 2 trong một bài post khác!!!
Dựa trên model
Sử dùng python xây dựng công cụ đề xuất
Khi nào thì cần sử dụng tính năng lọc cộng tác
Kết luận
Tài liệu tham khảo:
Paper research:http://files.grouplens.org/papers/www10_sarwar.pdf







{kind=link}